Исследование эффективности нечеткого МГУА с различными видами частных описаний и алгоритмами адаптации в задачах прогнозирования 2 часть
3. Адаптация коэффициентов линейной интервальной модели
При прогнозировании с использованием методов самоорганизации (в частности, нечеткого МГУА) возникает проблема, связанная с необходимостью проведения большого объема повторных вычислений при увеличении числа точек обучающей последовательности хотя бы на единицу, а также при прогнозировании в режиме реального времени, когда желательно быстро откорректировать имеющуюся модель в соответствии с полученными новыми данными.
В работе для решения этой проблемы предложено использовать следующие методы пошаговой адаптации коэффициентов нечеткой прогнозирующей модели: стохастическая аппроксимация и рекурсивные методы идентификации – РМНК и фильтр Калмана.
Необходимость исследования сразу нескольких алгоритмов адаптации коэффициентов нечеткой модели вызвана в значительной степени тем, что алгоритм стохастической аппроксимации, несмотря на все его преимущества, является несколько искусственной надстройкой над алгоритмом НМГУА и имеет следующий недостаток: при формировании оценки первого из последовательности корректирующих коэффициентов никак не учитывается информация, полученная при оценивании вектора параметров модели по ходу алгоритма НМГУА. Кроме того, возможность выбора одного из нескольких алгоритмов адаптации позволяет провести более широкие экспериментальные исследования и разработать рекомендации относительно использования алгоритмов адаптации в задачах прогнозирования.
Учитывать информацию, полученную при оценивании вектора параметров модели для инициализации алгоритма пошаговой адаптации, возможно путем использования рекурсивных методов идентификации. В этом случае выходом алгоритма НМГУА является модель оптимальной сложности вместе с данными, которые накопились при оценивании вектора ее параметров, и их можно использовать для модификации параметров в соответствии с полученными новыми измерениями, т.е. оценка параметров на следующем шаге формируется на основе оценки параметров на предыдущем шаге, погрешности модели и некоторой информационной матрицы, которая модифицируется на протяжении процесса оценивания. При этом адаптация коэффициентов модели кардинально упрощается – если сохранить информационную матрицу, полученную при идентификации параметров модели оптимальной сложности, структура которой получена с помощью НМГУА, то для адаптации параметров модели достаточно будет сделать одну итерацию соответствующим методом рекурсивной идентификации.
В [5] показано, что наилучшими алгоритмами адаптации оказывается рекуррентный алгоритм адаптации, а именно рекуррентный МНК и фильтр Калмана.
4. Описание проведенных экспериментов
Для проведения экспериментов по моделированию и прогнозированию макроэкономических процессов в Украине использовалась база данных, которая содержит ежемесячные измерения 24 макроэкономических параметров украинской экономики от июля 1995 года по июль 2004 года.
Объектами моделирования был выбран индекс потребительских цен (ИПЦ) и валовой внутренний продукт (ВВП).
При построении прогнозирующих моделей использовалась технология “скользящего окна”, размер которого определялся автоматически с помощью методов регрессионного анализа. При определении переменных, которые являются существенными для моделирования (то есть такими, которые вводятся в модель как входные), также использовались методы регрессионного анализа.
Были проведены следующие эксперименты:
1. Сравнительный анализ предложенных алгоритмов идентификации и адаптации на основе решения задачи прогнозирования макроэкономических показателей экономики Украины и России с целью определения наилучших из них.
С этой целью были проведены следующие экспериментальные исследования:
• построение прогнозирующих моделей с использованием треугольной, гауссовской и колоколообразной функций принадлежности;
• построение прогнозирующих моделей, которые базируются на разных видах частных описаний (классическом, полиноме Чебышева, полиноме Лагерра, тригонометрические полиномы, модели авторегрессии скользящего среднего (АРСС)) как с пошаговой адаптацией коэффициентов, так и без нее;
2. Сравнительный анализ предложенных алгоритмов с классическими, которые широко применяются в задачах прогнозирования, в частности: РМНК; нейронные сети с обратным распространением (back propagation); классический алгоритм МГУА.
Были проведены также следующие сравнительные исследования:
• сравнение качества прогнозов, полученных с помощью классических алгоритмов и с помощью НМГУА с использованием стандартных частных описаний без пошаговой адаптации коэффициентов и с использованием разных алгоритмов пошаговой адаптации коэффициентов (стохастической аппроксимации, РМНК);
• сравнение качества прогнозов, полученных с помощью классических алгоритмов и с помощью НМГУА с использованием разных видов частных описаний (классического, полиномов Чебышева, полиномов Лагерра, тригонометрических полиномов, АРСС-моделей) без пошаговой адаптации коэффициентов, а также с использованием разных алгоритмов пошаговой адаптации коэффициентов.
5. Анализ полученных результатов
1. Сравнение разных функций принадлежности
В данной серии экспериментов были проведены исследования нечетких прогнозирующих моделей со следующими функциями принадлежности нечетких параметров: треугольной, гауссовской и колоколообразной. Среднее значение среднеквадратичного отклонения (СКО) на всем диапазоне исследуемых данных при прогнозировании ИПЦ приведено на рис.2.
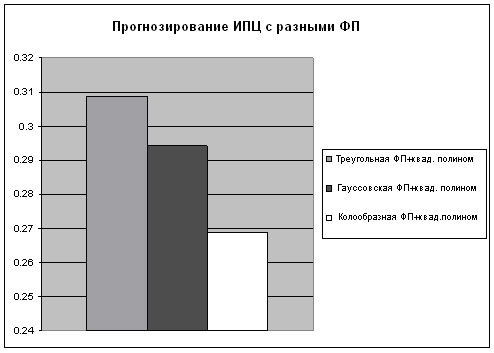
Как видим, наиболее эффективными для построения линейных интервальных моделей являются коэффициенты с колоколообразной функцией принадлежности. Также отметим незначительное преимущество гауссовской ФП над треугольной.
Аналогичная диаграмма при прогнозировании ВВП имеет вид рис.3.
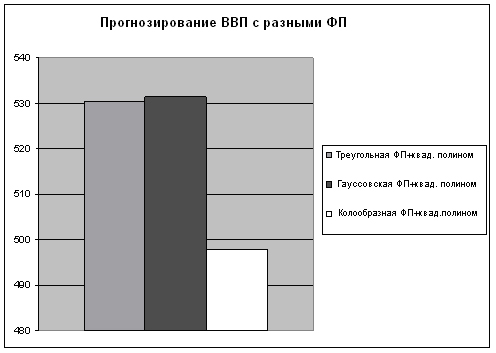
Как видим, общая картина почти не изменилась – наилучшее качество прогноза достигают модели с колоколообразной функцией принадлежности, отметим также тот факт, что в данном случае треугольная ФП более эффективна чем гауссовская.
2. Сравнение разных видов частных описаний
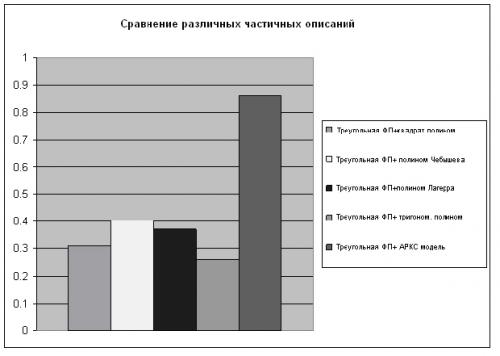
Далее были проведены экспериментальные исследования со следующими частными описаниями: квадратичными полиномами, полиномами Чебышева, полиномами Лагерра, тригонометрическими полиномами и АРСС-моделями. На диаграммах рис.4, 5 указано среднее значение СКО на всем диапазоне данных при прогнозировании ИПЦ и ВВП без пошаговой адаптации коэффициентов – с целью сравнить эффективность алгоритмов.
При прогнозировании ИПЦ получены следующие результаты.
При прогнозировании с использованием методов самоорганизации (в частности, нечеткого МГУА) возникает проблема, связанная с необходимостью проведения большого объема повторных вычислений при увеличении числа точек обучающей последовательности хотя бы на единицу, а также при прогнозировании в режиме реального времени, когда желательно быстро откорректировать имеющуюся модель в соответствии с полученными новыми данными.
В работе для решения этой проблемы предложено использовать следующие методы пошаговой адаптации коэффициентов нечеткой прогнозирующей модели: стохастическая аппроксимация и рекурсивные методы идентификации – РМНК и фильтр Калмана.
Необходимость исследования сразу нескольких алгоритмов адаптации коэффициентов нечеткой модели вызвана в значительной степени тем, что алгоритм стохастической аппроксимации, несмотря на все его преимущества, является несколько искусственной надстройкой над алгоритмом НМГУА и имеет следующий недостаток: при формировании оценки первого из последовательности корректирующих коэффициентов никак не учитывается информация, полученная при оценивании вектора параметров модели по ходу алгоритма НМГУА. Кроме того, возможность выбора одного из нескольких алгоритмов адаптации позволяет провести более широкие экспериментальные исследования и разработать рекомендации относительно использования алгоритмов адаптации в задачах прогнозирования.
Учитывать информацию, полученную при оценивании вектора параметров модели для инициализации алгоритма пошаговой адаптации, возможно путем использования рекурсивных методов идентификации. В этом случае выходом алгоритма НМГУА является модель оптимальной сложности вместе с данными, которые накопились при оценивании вектора ее параметров, и их можно использовать для модификации параметров в соответствии с полученными новыми измерениями, т.е. оценка параметров на следующем шаге формируется на основе оценки параметров на предыдущем шаге, погрешности модели и некоторой информационной матрицы, которая модифицируется на протяжении процесса оценивания. При этом адаптация коэффициентов модели кардинально упрощается – если сохранить информационную матрицу, полученную при идентификации параметров модели оптимальной сложности, структура которой получена с помощью НМГУА, то для адаптации параметров модели достаточно будет сделать одну итерацию соответствующим методом рекурсивной идентификации.
В [5] показано, что наилучшими алгоритмами адаптации оказывается рекуррентный алгоритм адаптации, а именно рекуррентный МНК и фильтр Калмана.
4. Описание проведенных экспериментов
Для проведения экспериментов по моделированию и прогнозированию макроэкономических процессов в Украине использовалась база данных, которая содержит ежемесячные измерения 24 макроэкономических параметров украинской экономики от июля 1995 года по июль 2004 года.
Объектами моделирования был выбран индекс потребительских цен (ИПЦ) и валовой внутренний продукт (ВВП).
При построении прогнозирующих моделей использовалась технология “скользящего окна”, размер которого определялся автоматически с помощью методов регрессионного анализа. При определении переменных, которые являются существенными для моделирования (то есть такими, которые вводятся в модель как входные), также использовались методы регрессионного анализа.
Были проведены следующие эксперименты:
1. Сравнительный анализ предложенных алгоритмов идентификации и адаптации на основе решения задачи прогнозирования макроэкономических показателей экономики Украины и России с целью определения наилучших из них.
С этой целью были проведены следующие экспериментальные исследования:
• построение прогнозирующих моделей с использованием треугольной, гауссовской и колоколообразной функций принадлежности;
• построение прогнозирующих моделей, которые базируются на разных видах частных описаний (классическом, полиноме Чебышева, полиноме Лагерра, тригонометрические полиномы, модели авторегрессии скользящего среднего (АРСС)) как с пошаговой адаптацией коэффициентов, так и без нее;
2. Сравнительный анализ предложенных алгоритмов с классическими, которые широко применяются в задачах прогнозирования, в частности: РМНК; нейронные сети с обратным распространением (back propagation); классический алгоритм МГУА.
Были проведены также следующие сравнительные исследования:
• сравнение качества прогнозов, полученных с помощью классических алгоритмов и с помощью НМГУА с использованием стандартных частных описаний без пошаговой адаптации коэффициентов и с использованием разных алгоритмов пошаговой адаптации коэффициентов (стохастической аппроксимации, РМНК);
• сравнение качества прогнозов, полученных с помощью классических алгоритмов и с помощью НМГУА с использованием разных видов частных описаний (классического, полиномов Чебышева, полиномов Лагерра, тригонометрических полиномов, АРСС-моделей) без пошаговой адаптации коэффициентов, а также с использованием разных алгоритмов пошаговой адаптации коэффициентов.
5. Анализ полученных результатов
1. Сравнение разных функций принадлежности
В данной серии экспериментов были проведены исследования нечетких прогнозирующих моделей со следующими функциями принадлежности нечетких параметров: треугольной, гауссовской и колоколообразной. Среднее значение среднеквадратичного отклонения (СКО) на всем диапазоне исследуемых данных при прогнозировании ИПЦ приведено на рис.2.
Как видим, наиболее эффективными для построения линейных интервальных моделей являются коэффициенты с колоколообразной функцией принадлежности. Также отметим незначительное преимущество гауссовской ФП над треугольной.
Аналогичная диаграмма при прогнозировании ВВП имеет вид рис.3.
Как видим, общая картина почти не изменилась – наилучшее качество прогноза достигают модели с колоколообразной функцией принадлежности, отметим также тот факт, что в данном случае треугольная ФП более эффективна чем гауссовская.
2. Сравнение разных видов частных описаний
Далее были проведены экспериментальные исследования со следующими частными описаниями: квадратичными полиномами, полиномами Чебышева, полиномами Лагерра, тригонометрическими полиномами и АРСС-моделями. На диаграммах рис.4, 5 указано среднее значение СКО на всем диапазоне данных при прогнозировании ИПЦ и ВВП без пошаговой адаптации коэффициентов – с целью сравнить эффективность алгоритмов.
При прогнозировании ИПЦ получены следующие результаты.
Комментарии (0)
RSS свернуть / развернутьТолько зарегистрированные и авторизованные пользователи могут оставлять комментарии.